
Verizon Connect
Verizon Connect
University of Bologna
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Bird’s Eye View (BEV) semantic maps have recently garnered a lot of attention as a useful representation of the environment to tackle assisted and autonomous driving tasks. However, most of the existing work focuses on the fully supervised setting, training networks on large annotated datasets. In this work, we present RendBEV, a new method for the self-supervised training of BEV semantic segmentation networks, leveraging differentiable volumetric rendering to receive supervision from semantic perspective views computed by a 2D semantic segmentation model. Our method enables zero-shot BEV semantic segmentation, and already delivers competitive results in this challenging setting. When used as pretraining to then fine-tune on labeled BEV ground truth, our method significantly boosts performance in low-annotation regimes, and sets a new state of the art when fine-tuning on all available labels.
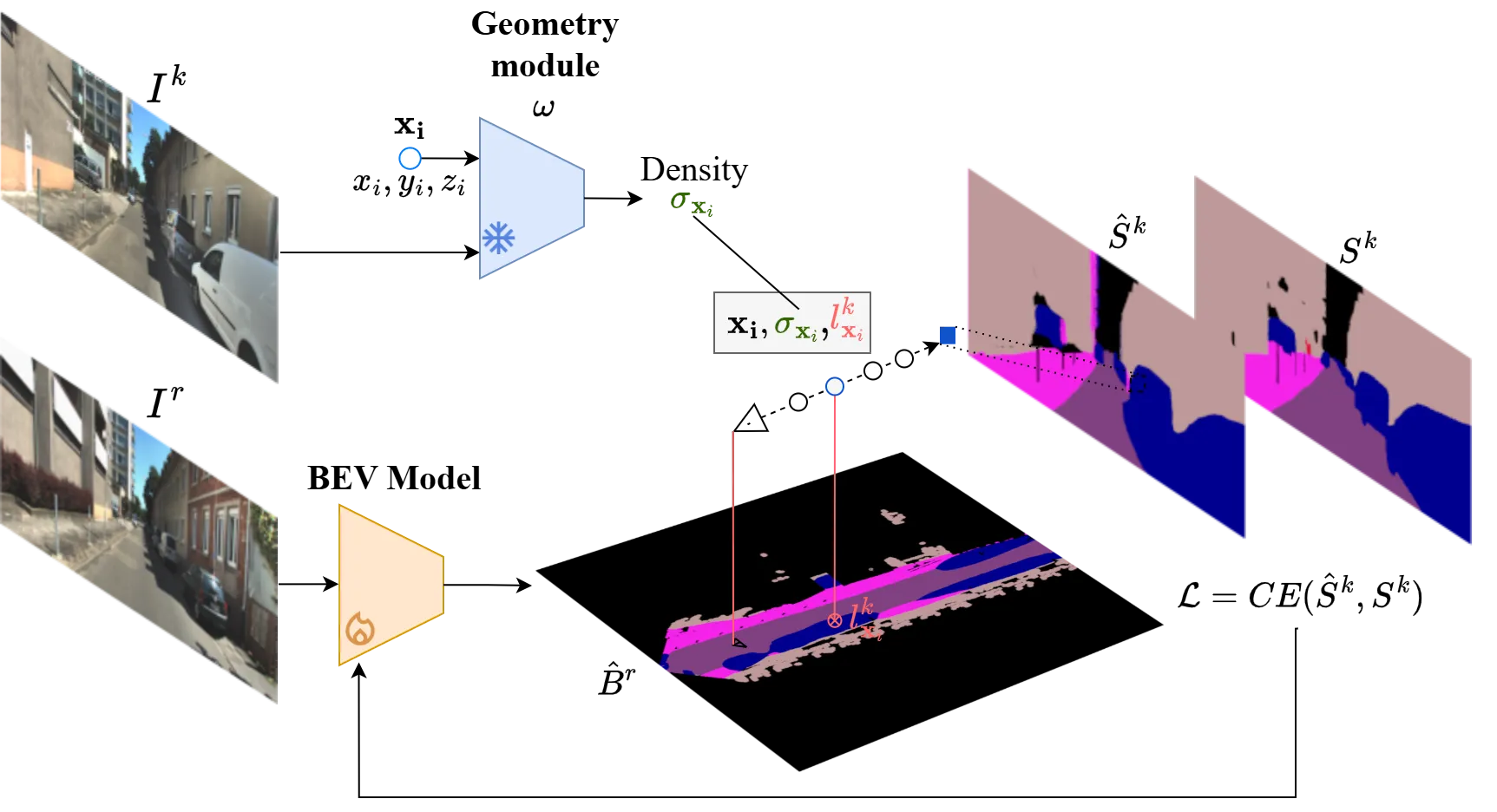
RendBEV, our method for self-supervised training of BEV semantic segmentation models: we perform a forward pass with a reference view as input of the BEV network. We render the semantic semantic segmentation of another view , with class probability values sampled from the BEV prediction and densities queried from a pretrained frozen model that receives the target frame as input. We supervise the network with a cross entropy loss computed with the rendered semantic segmentation and the target semantic segmentation .
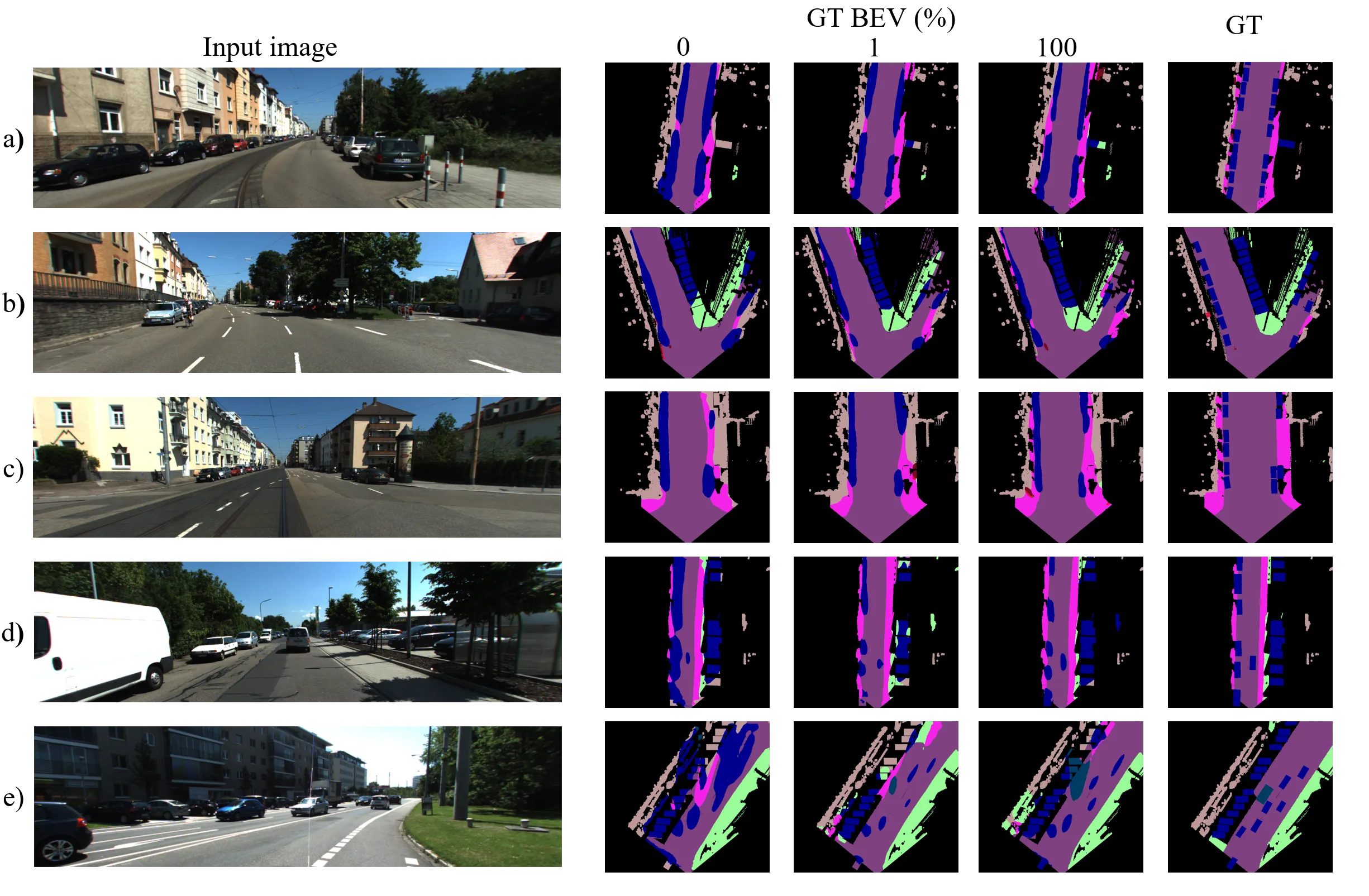
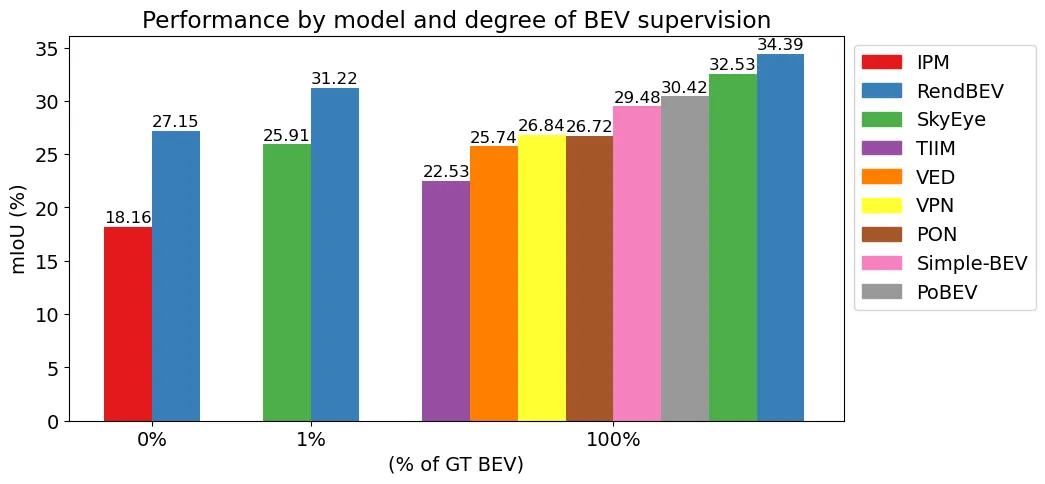
We use the KITTI-360 dataset for training and evaluation, accesible here. We use the Waymo Open Dataset for evaluation only, accesible here. We employ the BEV semantic labels of this datasets provided by the authors of SkyEye. We thank the creators of these datasets for making them publicly accesible.
Henrique Piñeiro Monteagudo is supported by the SMARTHEP project, funded by the European Union’s Horizon 2020 research and innovation programme, call H2020-MSCA-ITN-2020, under Grant Agreement n. 956086
@INPROCEEDINGS{pineiro25rendbev,
authors = "{Piñeiro Monteagudo, Henrique and Taccari, Leonardo and Pjetri, Aurel and Sambo, Francesco and Salti, Samuele}",
booktitle={2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
title = "RendBEV: Semantic Novel View Synthesis for Self-Supervised Bird's Eye View Segmentation",
year = "2025",
}